









Table of contents
The National Vulnerability Database Explained

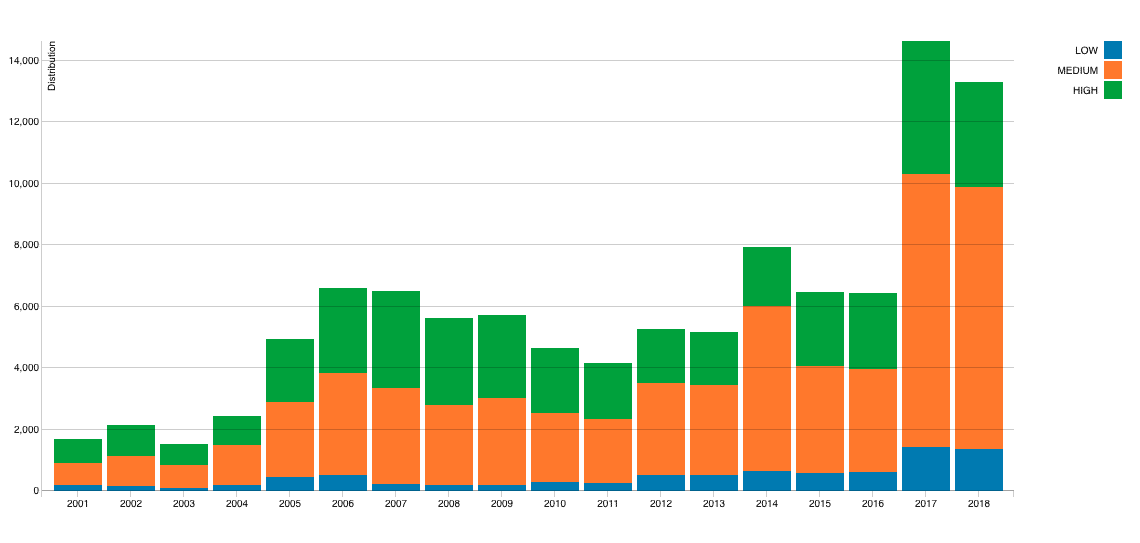
The National Vulnerability Database (NVD) is the largest and most comprehensive database of reported known vulnerabilities, both in commercial and open source components.
Although the NVD has been getting some bad rep in recent years as it doesn’t include all reported security issues and new open source security vulnerability databases which aggregate multiple sources are starting to get more traction, it is still a crucial resource in the ongoing struggle to keep our applications safe, providing developers and security professionals with the information they need to detect and fix new published known vulnerabilities. This is because the NVD provides an easy to navigate database platform that includes an analysis not found in other public resources.
Established in 2005, the NVD is operated under the auspices of the U.S. National Institute of Standards and Technology (NIST). It is sponsored by the Department of Homeland Security’s National Cybersecurity and Communications Integration Center, and by Network Security Deployment.
If you are a developer or security team member, the NVD can help keep your organization’s software safe, if you know how to take advantage of the information being provided.
What kind of information is in an NVD posting?
Within a posting on the NVD, visitors can find a breakdown of many of the details about a software security vulnerability, to help them understand what they are dealing with and what their next steps should be.
This includes a description of the CVE and the source of the information, which is generally from the MITRE Corporation. Then we are given a picture of how dangerous a specific vulnerability can be in the impact section. Based on the CVSS v2 and CVSS v3 Severity and Metrics, the NVD tells readers how the vulnerability has been rated (Critical, High, Medium, Low), as well as details about how the exploitation could actually be carried out.
There are also helpful links to information that is not listed on the National Vulnerability Database itself that will take you to outside advisories where you can find additional solutions and tools. The NVD makes a point of not endorsing these external sources but apparently finds them helpful enough to include.
Finally, the good folks at the NVD provide readers with a quick history of the particular CVE, including when it was first published on MITRE’s CVE dictionary, as well as posting dates on the NVD itself.
How the national vulnerability database differs from the CVE
The National Vulnerability Database is often spoken of interchangeably with the Common Vulnerabilities and Exposures (CVE) list but there are some differences between the two resources despite having a very close relationship. After all, they are both sponsored by the same organizations and serve the purpose of informing the community of risks to their software.
First off, they are actually two different lists, run by separate organizations. The CVE dictionary was launched in 1999, five years before the NVD, and is run by the non-profit MITRE Corporation which was mentioned above.
Whereas the NVD is a more robust dataset describing the vulnerabilities, the CVE dictionary is more barebones, providing the straight facts of the CVE ID number (CVE-year-unique id #), as well as one public link.
Despite their differences, the two databases work hand-in-hand, making the information more accessible for the readers. To put it simply, the CVE is the organization that receives submissions and IDs them, while the NVD adds the analysis and makes it easier to search and manage them.
The story of how a vulnerability makes its way to the NVD is fairly standard, starting with its initial submission to the CVE.
The vulnerability publishing roadmap
When a vulnerability is discovered by a security researcher or company, in many cases they will inform the CVE to reserve an ID. This information will stay private for a period of 60-90 days to give the owner of the product or open source project time to find a fix to the vulnerability and update relevant vendors if necessary before the word of the exploit becomes public.
This publication of vulnerabilities can be a double-edged sword in that it is essential that developers and users of software receive the necessary information to keep themselves protected. At the same time, there is always the risk that a hacker might find the information posted on the NVD first and then target organizations who have been too slow to patch.
After the CVE receives the information about the exploit, they will pass it on to the National Vulnerability Database for analysis. The NVD relies solely on the CVE for its feed of submitted vulnerabilities and does not perform any of its own searches for vulnerabilities in the wild.
It should be said that the NVD will respect the grace period as well, and will hold off on publishing anything until it is no longer “Reserved” by the CVE. Once a CVE is posted to the NVD, it will likely stay there unless someone brings a serious dispute to prove that it should be taken down. This means that the NVD has turned into a pretty exhaustive and dependable database that will continue to grow over time.
Limitations of the NVD for securing open source components
The biggest problem that the National Vulnerability Database faces when it comes to helping organizations work securely with open source components is not actually their fault.
As we noted above, the NVD receives its vulnerability listings directly from the CVE. Therefore, vulnerabilities that are not reported to the CVE will not make it onto the NVD. Unlike the commercial software sector which manages its code under one roof, the open source community is far more diffused and is harder to organize.
While there is generally a manager for an open source project who can be sent discoveries of vulnerabilities and then pass those onto the CVE, sometimes this information will pop up in other resources like security advisories, forums, and other spots online that are not being monitored, meaning that they will not make its way to the primary lists.
The secondary problem is that many organizations simply are not aware of which open source components they are using in their software products. Therefore, even if they write an API to get updates for every single new CVE that comes into the NVD, they still would have to go through their product and search for these components to see if they are relevant.
This process is hardly scalable for organizations hoping to get any other work done this month.
How to take full advantage of the NVD
To solve this challenge, many organizations have turned to Software Composition Analysis (SCA) tools which can identify which open source components are being used in their projects, tracking information from across a variety of resources.
As a community working to build better, more secure software, we need to take full advantage of everything the National Vulnerability Database has to offer and appreciate them for all of their contributions. We also need to take responsibility for our development, understanding the limitations that are inherent to the NVD and incorporate solutions to keep our products safe.


